随着数据量的爆炸式增长和业务需求的多样化,分布式存储系统在现代IT架构中扮演着至关重要的角色。curve作为一种高性能、高可靠的分布式存储系统,吸引了众多开发者和企业的关注。本文将深入探讨curve分布式存储系统的软件开发过程,涵盖核心概念、架构设计、开发流程和最佳实践,帮助读者全面理解和掌握curve的开发与应用。
一、curve分布式存储系统概述
curve是一个开源的分布式存储系统,旨在提供高效的数据存储和管理解决方案。其核心设计理念包括高可用性、强一致性和水平扩展性。curve支持块存储和文件存储,适用于云计算、大数据分析和容器化环境等场景。通过采用先进的算法和架构,curve能够有效降低延迟、提高吞吐量,并确保数据的安全性和持久性。
二、curve系统架构与核心组件
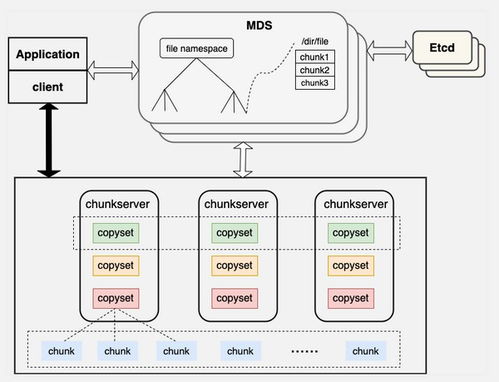
curve的架构主要包括以下关键组件:
- 元数据服务(Metadata Service):负责管理存储系统的元数据,如文件目录、块映射等,确保数据的一致性和快速访问。
- 数据存储服务(Data Storage Service):处理实际数据的读写操作,采用分布式存储机制将数据分散到多个节点,实现负载均衡和故障恢复。
- 客户端SDK(Client SDK):为应用程序提供易用的API,支持多种编程语言,简化集成过程。
- 监控和管理模块(Monitoring and Management):实时监控系统状态,提供日志记录、性能分析和自动化运维功能。
这些组件通过高效的通信协议协同工作,形成一个可靠的分布式存储集群。开发者需要理解各组件间的交互方式,以便在开发过程中进行优化和故障排查。
三、curve软件开发流程
curve的软件开发通常遵循以下步骤:
- 环境准备:安装必要的依赖项,如C++编译器、CMake构建工具和分布式系统库。curve官方文档提供了详细的环境配置指南,建议使用Docker容器或虚拟机进行开发测试。
- 代码获取与编译:从GitHub等平台克隆curve源代码,使用CMake编译生成可执行文件。开发者可以根据需求自定义编译选项,例如启用调试模式或优化性能。
- 功能开发与测试:根据业务需求,添加新功能或修改现有模块。curve采用单元测试和集成测试相结合的方式,确保代码质量。建议使用模拟环境进行压力测试,验证系统在高负载下的稳定性。
- 部署与运维:将开发完成的系统部署到生产环境,配置集群节点和网络参数。curve提供了自动化部署工具,如Ansible脚本,简化运维流程。
四、最佳实践与常见挑战
在curve软件开发中,开发者应注意以下最佳实践:
- 性能优化:利用curve的缓存机制和并行处理能力,减少I/O延迟。例如,通过调整数据分片大小和副本策略,平衡存储效率与可靠性。
- 容错处理:设计健壮的错误处理机制,应对节点故障或网络分区问题。curve内置了数据恢复功能,但开发者需确保应用程序能正确处理异常情况。
- 安全性与合规性:实施数据加密和访问控制,保护敏感信息。curve支持TLS/SSL传输加密和基于角色的权限管理,建议结合企业安全策略进行配置。
常见挑战包括分布式一致性的维护、大规模集群的管理以及与其他系统的集成。通过参与curve社区和参考案例研究,开发者可以快速解决这些问题。
五、总结与展望
curve分布式存储系统以其灵活性和高性能,成为现代软件开发的重要工具。通过掌握其架构和开发流程,开发者能够构建可扩展的存储解决方案,满足日益增长的数据需求。未来,curve将继续演进,融入AI驱动的优化和边缘计算支持,为分布式存储领域带来更多创新。鼓励开发者积极参与开源贡献,共同推动curve生态系统的发展。